Chapter 3 HTML Fundamentals
A webpage on the internet is basically a set of files that the browser renders (shows) in a particular way, allowing the user to interact with it. The most basic way to control how a browser displays content (e.g., words, images, etc) is by encoding that content in HTML.
HTML (HyperText Markup Language) is a language that is used to give meaning to otherwise plain text, which the browser can then use to determine how to display that text. HTML is not a programming language but rather a markup language: it adds additional details to information (like notes in the margin of a book), but doesn’t contain any logic. HTML is a “hypertext” markup language because it was originally intended to mark up a document with hyperlinks, or links to other documents. In modern usage, HTML describes the semantic meaning of textual content: it marks what text is a heading, what text is a paragraph, what content is an image, what text is a hyperlink, and so forth. In this sense HTML serves a similar function to the Markdown markup language, but is much more expressive and powerful.
This chapter provides an overview and explanation of HTML’s syntax (how to write it to annotate content). HTML’s syntax is very simple, and generally fast to learn—though using it effectively can require more practice. For more details on using HTML effectively, see Semantic HTML.
3.1 HTML Elements
HTML content is normally written in .html files. By using the .html extension, your editor, computer, and browser should automatically understand that this file will contain text content that includes HTML markup.
As mentioned in Chapter 2, most web servers will by default serve a file named index.html, and so that filename is traditionally used for a website’s home page.
As with all programming languages, .html files are really just plain text files with a special extension, so can be created in any text editor. However, using a coding editor such as VS Code provides additional helpful features that can speed up your development process.
HTML files contain the content of your web page: the text that you want to show on the page. This content is then annotated (marked up) by surrounding it with tags:

Basic syntax for an HTML element.
The opening/start tag comes before the content and tell the computer “I’m about to give you content with some meaning”, while the closing/end tag comes after the content to tell the computer “I’m done giving content with that meaning.” For example, the <h1> tag represents a top-level heading (equivalent to one # in Markdown), and so the open tag says “here’s the start of the heading” and the closing tag says “that’s the end of the heading”.
Tags are written with a less-than symbol <, then the name of the tag (often a single letter), then a greater-than symbol >. A closing tag is written just like an opening tag, but includes a forward slash / immediately after the less-than symbol—this indicates that the tag is closing the annotation.
HTML tag names are not case sensitive, but you should always write them in all lowercase—see the Code Style Guide for details.
Line breaks and white space around tags (including indentation) are ignored. Tags may thus be written on their own line, or inline with the content. These two uses of the <p> tag (which marks a paragraph of content) are equivalent:
<p>
The itsy bitsy spider went up the water spout.
</p>
<p>The itsy bitsy spider went up the water spout.</p>Nevertheless, when writing HTML code, use line breaks and spacing for readability (to make it clear what content is part of what element)—again, refer to the Code Style Guide.
Taken together, the tags and the content they contain are called an HTML Element. A website is made of a bunch of these elements—in fact, all content is annoted so that it is part of some element.
Some Example Elements
The HTML standard defines lots of different elements, each of which marks a different meaning for the content. Common elements include:
<h1>: a 1st-level heading<h2>: a 2nd-level heading (and so on, down to<h6>)<p>: a paragraph of text<a>: an “anchor”, or a hyperlink<img>: an image<button>: a button<em>: emphasized content. Note that this doesn’t mean italic (which is not semantic), but emphasized (which is semantic). The same as_text_in Markdown.<strong>: important, strongly stated content. The same as**text**in Markdown<ul>: an unordered list (and<ol>is an ordered list)<li>: a list item (an item in a list)<table>: a data table<form>: a form for the user to fill out<div>: a division (section) of content. Also acts as an empty block element (one followed by a line break)
And lots more!
Element names are defined by the HTML specification—often they are abbreviations for what they represent (e.g., <p> for paragraph). In standard HTML you can only use elements that are defined by the specification; you are not allowed to “make up” your own tags. Trying to use a <paragraph> instead of a <p> would be non-standard and wouldn’t be understood or rendered correctly by the browser.
You don’t need to memorize every HTML element type (though you will learn the common ones by heart by happenstance); you can always look up more details about specific element types. For many people “knowing” HTML is about knowing what elements exist in the standard, and the proper ways to combine those elements.
See Semantic HTML for more examples and discussion of specific HTML elements.
Attributes
The start tag of an element may also contain one or more attributes. These are similar to attributes in object-oriented programming: they specify properties, options, or otherwise add additional meaning to an element. Like named parameters in R or python, attributes are written in the format attributeName=value (no spaces are allowed around the =); values of attributes are almost always strings, and so are written in quotes. Multiple attributes are separated by spaces:
<tag attributeA="value" attributeB="value">
content
</tag>For example, a hyperlink anchor (<a>) uses a href (“hypertext reference”) attribute to specify where the browser should navigate to when the content is clicked:
<a href="https://ischool.uw.edu">iSchool homepage</a>In a hyperlink, the content of the tag is the displayed text, and the attribute specifies the link’s URL. This means that the URL comes “before” the displayed text—the opposite of Markdown hyperlink syntax.
Similarly, an image (<img>) uses the src (source) attribute to specify what picture it is showing. (That hyperlink use href and images use src is one of the many quirks of HTML syntax). An image’s alt attribute contains alternate text to use if the browser can’t show images—such as with screen readers (for the visually impaired) and search engine indexers.
<img src="baby_picture.jpg" alt="a cute baby">Because an <img> has no textual content, it is an empty element (see below).
Allowable attributes and their names are determined by the HTML specification—each element supports a certain set of attributes (see the HTML attribute reference). Many attributes are supported by some elements and not by others. However, there are also a number of global attributes that can be used on any element. For example:
Every HTML element can include an
idattribute, which is used to give it a unique identifier so that you can refer to it later (e.g., from JavaScript).idattributes are named like variable names, and must be unique on the page.<h1 id="title">My Web Page</h1>The
idattribute is most commonly used used to create “bookmark hyperlinks”, which are hyperlinks to a particular location on a page (i.e., that cause the page to scroll down to that location). You do this by including theidas the fragment of the URL to link to (e.g., after the#in the URL).<a href="index.html#nav">Link to element on `index.html` with `id="nav"`</a> <a href="#title">Link to element on current page with `id="title"`</a>Note that, when specifying an id (i.e.,
<h1 id="title">) you do not include the#symbol. However, to link to an element with idtitle, you include the#symbol before the id (i.e.,<a href="#title">)Every HTML element can include a
classattribute, which is used to specify what CSS classes apply to it. See CSS Fundamentals for more details.The
langattribute is used to indicate the language in which the element’s content is written. Programs reading this file might use that to properly index the content, correctly pronounce it via a screen reader, or even translate it into another language:<p lang="sp">No me gusta</p>The
langattribute is primarily specified for the<html>element (see below) to define the default language of the page; that way you don’t need to mark the language of every element.<html lang="en">
Note that some attributes are written without an explicit value, meaning the value is the boolean true (for the value to be false, you omit the attribute entirely). For example, a <button> can be disabled:
<!-- the presence of the `disabled` means the value is `true` -->
<button disabled>You can't click me because I'm turned off</button>Empty Elements
A few HTML elements don’t require a closing tag because they can’t contain any content. These elements are often used for inserting media into a web page, such as the <img> element. With an <img> element, you can specify the path to the image file in the src attribute, but the image element itself can’t contain additional text or other content. Since it can’t contain any content, you omit the end tag entirely:
<img src="picture.png" alt="description of image for screen readers and indexers">Older versions of HTML (and current related languages like XML) required you to include a forward slash / just before the ending > symbol. This “closing” slash indicated that the element was complete and expected no further content—what is called a self-closing tag:
<img src="picture.png" alt="description of image for screen readers and indexers" />This is no longer required in HTML5, so feel free to omit that forward slash (though some purists, or those working with XML, will still include it). You will also need to include the closing / on empty elements when writing HTML for React apps.
3.2 Nesting Elements
Web pages are made up of multiple (hundreds! thousands!) of HTML elements. Moreover, HTML elements can be nested: that is, the content of an HTML element can contain other HTML tags (and thus other HTML elements):

An example of element nesting: the <em> element is nested in the <h1> element’s content.
The semantic meaning indicated by an element applies to all its content: thus all the text in the above example is a top-level heading, and the content “(with emphasis)” is emphasized in addition.
Because elements can contain elements which can themselves contain elements, an HTML document ends up being structured as a “tree” of elements:
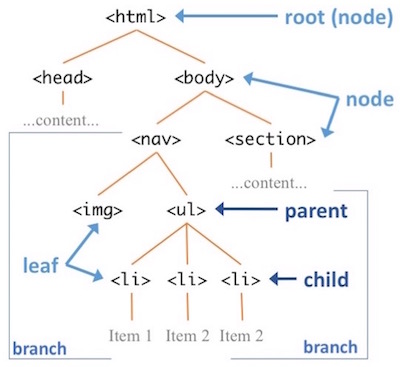
An example DOM tree (a tree of HTML elements).
In an HTML document, the “root” element of the tree is always an <html> element. Inside this we put a <body> element to contain the document’s “body” (that is, the shown content):
<html lang="en">
<body>
<h1>Hello world!</h1>
<p>This is <em>conteeeeent</em>!</p>
</body>
</html>This model of HTML as a tree of “nodes”—along with an API (programming interface) for manipulating them— is known as the Document Object Model (DOM). See Document Object Model (DOM) for details.
Following the “tree” structure metaphor, you refer an element as being the parent of any element it contains, and the contained element as the child. In the above example, the <em> element is the child of the <p> element, and the <p> element is the parent of the <em> element. The <body> is a child of the <html>, and the parent of the <h1> and the <p>.
Caution! HTML elements have to be “closed” correctly, or the semantic meaning may be incorrect! If you forget to close the <h1> tag, then all of the following content will be considered part of the heading! Remember to close your inner tags before you close the outer ones. Validating your HTML can help find errors in this.
Nesting elements is fundamental to HTML; in fact, all elements on the page are the child of some other element (except the <html> at the root). For example, a list can be specified by nesting list item (<li>) elements inside of an unordered list (<ul>) element. And of course, those <li> elements can contain even more elements, such as additional ordered list (<ol>) elements!
<!-- An unordered list <ul> with 3 items <li>. The second item's content
contains another ordered list <ol> containing 2 items. -->
<ul>
<li>Pigeons</li>
<li>
Swallows:
<ol>
<li>African</li>
<li>European</li>
</ol>
</li>
<li>Budgies</li>
</ul>This example has elements nested 4 levels deep (and that’s relatively shallow for HTML). Note that the second <li> contains text (the word “Swallows:”) as well as an additional element (an <ol>)—but all of that is content of the element!
Block vs. Inline Elements
All HTML elements fall into one of two categories:
Block elements form a visible “block” on a page. In particular, a block element will be rendered below (on a “new line” from) from the previous content, and any content after it will be rendered below it. Block elements tend to be structural elements for a page: headings (
<h1>), paragraphs (<p>), lists (<ul>), etc.<p>Block element</p> <p>Block element</p>
Two block elements rendered on a page.
Inline elements are contained “in the line” of content. These will not have a “line break” after them. Inline elements are used to modify the content rather than set it apart, such as giving it emphasis (
<em>) or declaring that it to be a hyperlink (<a>).<em>Inline element</em> <em>Other inline element</em>
Two inline elements rendered on a page.
So in general, block elements are used to specify the “parts” of the page or annotate large blocks of content, while inline elements annote parts of that content (individual words or phrases).
When nesting elements, inline elements can go inside of block elements or other inline elements, and it’s common to put block elements inside of the other block elements (e.g., an <li> inside of a <ul>, or a <p> inside of a <div>). However, it is invalid to nest a block element inside of an inline element. For example, you can’t put a <p> inside of an <em> to say that the paragraph is emphasized (it would need to go the other way around). The one exception is that you are allowed to nest block elements inside of <a> elements to turn the entire block into a hyperlink, though this isn’t very common.
Some elements have further restrictions on nesting. For example, a <ul> (unordered list) is only allowed to contain <li> elements—anything else is considered invalid markup.
Each element has a different default display type (e.g., block or inline, but it is also possible to change how an element is displayed using CSS. See the display property.
3.3 Web Page Structure
As noted above, HTML documents always follow a particular structure, with all of the content nested inside of a single <html> element. Thus web documents all use the following “template”:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="author" content="your name">
<meta name="description" content="description of your page">
<title>My Page Title</title>
</head>
<body>
...
Content goes here!
...
</body>
</html>(Alternatively, you can use the VS Code shortcut of writing an exclamation point (!) then hitting the tab key in a .html file to create a similar page skeleton).
There are a few parts and elements to this template:
Doctype Declaration. All HTML files start with a document type declaration, commonly referred to as the “Doctype.” This tells the rendering program (e.g., the browser) what format and syntax your document is using. Since your web document is written in HTML 5, you declare it as
<!DOCTYPE html>.<!DOCTYPE>isn’t technically an HTML tag (it’s actually XML). While modern browsers will perform a “best guess” as to the Doctype, it is best practice to specify it explicitly. Always include the Doctype at the start of your HTML files!The
<html>element: The<html>element is the “start” of the HTML document (the whole document is contained within that element). Specify alangattribute for this element.The
<html>element contains exactly two child elements: a<head>and a<body>. No other elements can go directly inside of the<html>.The
<head>element: The<head>element contains metadata for the document—data about the content that isn’t displayed on the page. It specifies information about the document being rendered. There are a couple of common elements you should include in the<head>:A
<title>, which specifies the “title” of the webpage:<title>My Page Title</title>Browsers will show the page title in the tab at the top of the browser window, and use that as the default bookmark name if you bookmark the page. But the title is also used by search indexers and screen readers for the blind, since it often provides a strong signal about what is the page’s subject. Thus your title should be informative and reflective of the content.
A
<meta>tag that specifies the character encoding of the page:<meta charset="UTF-8">The
<meta>tag itself represents “metadata” (information about the page’s data), and uses an attribute and value to specify that information. The most important<meta>tag is for the character set, which tells the browser how to convert binary bits from the server into letters. Nearly all editors these days will save files in theUTF-8character set, which supports the mixing of different scripts (Latin, Cyrillic, Chinese, Arabic, etc) in the same file.You can also use the
<meta>tag to include more information about the author, description, and keywords for your page:<meta name="author" content="your name"> <meta name="description" content="description of your page"> <meta name="keywords" content="list,of,keywords,separate,by,commas">Note that the
nameattribute is used to specify the “variable name” for that piece of metadata, while thecontentattribute is used to specify the “value” of that metadata.<meta>elements are empty elements and have no content of their own.Again, these are not visible in the browser window (because they are in the
<head>!), but will be used by search engines to index your page.- At the very least, always include author information for on the home page of sites you create!
Additional elements for the
<head>section will be introduced in later chapters, such as using<link>to include CSS and using<script>to include JavaScript.Note that the
<head>is different from a header element (like an<h1>), as well as from the<header>element discussed in Semantic HTML.The
<body>element: The<body>element contains all of the visible content of the web page. Every heading, paragraph, image, form, etc goes inside of the<body>. Note that you cannot put any visible elements outside of the<body>—not in the<head>or directly in the<html>. Header and footer content are still part of the<body>of the page!
Resources
Some useful references and documentation as you begin learning HTML include:
The first reference is from the Mozilla Developer Network (MDN). This reference is managed by Mozilla, the organization that creates and maintains the Firefox web browser. It is the most detailed and accurate reference for web programming, and is what I consider the closest “documentation” for code syntax.
The second reference is from W3Schools, and is a very friendly beginner reference for many web development topics. However, it is somewhat less extensive and accurate than MDN.
Also remember you can view the HTML page source of any webpage you visit. Use that to explore how others have developed pages and to learn new tricks and techniques!
Comments
As with every programming language, HTML includes a way to add comments to your code. It does this by using a tag with special syntax:
The contents of the comment tag (between the
<!--and the-->) can span multiple lines, so you can comment multiple lines by surrounding them all with a single<!--and-->.Because the comment syntax is somewhat awkward to type, most source-code editors will let you comment-out the currently highlighted text by pressing
cmd + /(orctrl + /on Windows). If you’re using a code editor, try placing your cursor on a line and using that keyboard command to comment and un-comment the line.Comments can appear anywhere in the file. Just as in other languages, they are ignored by any program reading the file, but they do remain in the page and are visible when you view the page source.